
يمكن القول بأن سباق الذكاء الاصطناعي العالمي دخل في مرحلة يمكن وصفها بـ "الحرب الباردة" مع إطلاق النموذج الصيني. ديب سيك" DeepSeek في بداية هذا الشهر، وقع حدث أحدث صدمة لم يسبق لها مثيل فيأسهم الشركات التقنية العالميةوجه تهديدًا واضحًا للسيطرة الأمريكية التي تجسدها شركات مثل Meta و OpenAI وغيرها في هذا المجال. استطاع تطبيق DeepSeek أن يتجاوز بسرعة منافسه. ChatGPT ليصبح التطبيق الأكثر تحميلًا عالميًا على كل من متجر التطبيقات ومتجر جوجل بلاي بعد أيام قليلة من إصداره للهواتف.
على الرغم من تشابه طريقة استخدامه مع أحدث النماذج المطورة في الغرب، إلا أنه يحدث تقدمًا نوعيًا في كفاءة التشغيل والتطوير. حيث تؤكد الشركة المطورة، التي تحمل نفس الاسم، أن نموذجها يتدرب بتكاليف أقل وبعدد شرائح أقل بكثير مقارنةً بالنماذج الغربية الرائدة. والأهم من ذلك، أنه مفتوح المصدر، مما يساهم في انتشاره بشكل أوسع وأسرع. لذا، دعونا نبدأ في السطور القادمة لكي نتعرف بعمق على بوت DeepSeek وما الذي يجعله يثير القلق إلى حد فقدان أسواق التقنية الأمريكية لأكثر من نصف تريليون دولار!

نموذج الذكاء الاصطناعي DeepSeek
ما هو بوت DeepSeek أصلًا ؟

بوت ذكاء اصطناعي تم تطويره من قبل شركة ناشئة صينية تُدعى "DeepSeek AI"، التي أُسست في عام 2023 على يد "ليانج وينفنج"، رئيس صندوق التحوط الكمي المدعوم بالذكاء الاصطناعي المعروف باسم High-Flyer. مثل روبوتات الدردشة التقليدية، يقوم المستخدم بكتابة استفسار أو طلب، ليقوم البوت بإنتاج إجابة نصية، بأداء يماثل أحدث نماذج الذكاء الاصطناعي، وبشكل مجاني تمامًا.
ظهر هذا البوت لأول مرة في أواخر ديسمبر 2024، عندما أعلنت الشركة عن إطلاقه مع الكشف عن النموذج الأساسي الذي يستند إليه، والذي يعرف باسم "DeepSeek-V3"يُعتبر من أقوى النماذج مفتوحة المصدر على مستوى العالم، حيث يحتوي على 671 مليار متغير، متفوقًا على أكبر نموذج مفتوح المصدر من شركة ميتا الذي يضم 405 مليارات متغير، بفارق يصل إلى حوالي 1.6 ضعف. وتُستخدم المتغيرات (Parameters) كمقياس لتحديد حجم المهارات والقدرات لنماذج الذكاء الاصطناعي، وتعكس هذه الأرقام مدى تطور النموذج وقدرته على أداء مجموعة متنوعة من المهام، مثل كتابة الأكواد، والترجمة، وإنشاء النصوص، بالإضافة إلى خاصية "التفكير المنطقي" قبل تقديم الإجابات."
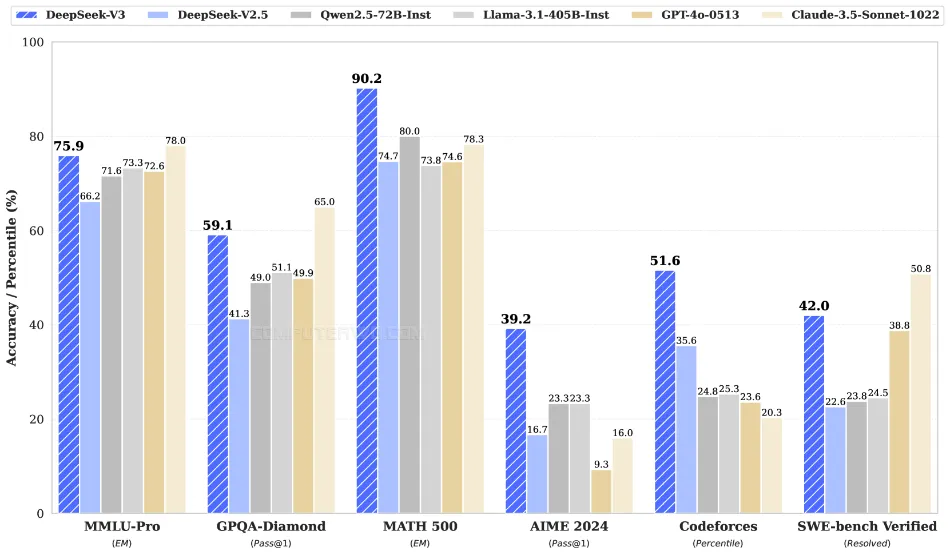
ووفقًا لاختبارات الأداء، أظهر DeepSeek-V3 تميزه مقارنة بالنماذج الرائدة مثل Llama 3.1 من ميتا و GPT-4 من OpenAI و Claude 3.5 من Anthropic. كما تشير الورقة البحثية أفادت الشركة المطورة أن النموذج قد تم تدريبه باستخدام قاعدة بيانات ضخمة تحتوي على 14.8 تريليون رمز، وهو ما يعادل نحو 750 ألف كلمة لكل مليون رمز، مما يبرز قدرته على معالجة كميات كبيرة من البيانات النصية.
الميزة الرئيسية في هذا النموذج هي أنه مفتوح المصدر تحت رخصة MIT، مما يتيح للجميع حرية استخدامه وتعديله وتطويره. وبخلاف ChatGPT الذي يعمل على خوادم OpenAI الخاصة فقط، يمكن تشغيل DeepSeek محليًا على أجهزة الكمبيوتر. حيث يتوفر نموذج DeepSeek-V3 للتنزيل عبر المنصات. GitHub و HuggingFace بالإضافة إلى إمكانية الاستفادة من مهاراته من خلال واجهة برمجية (API) تقدم الشركة أسعاراً تنافسية أقل بكثير من تلك الخاصة بنماذج OpenAI.

على الرغم من ذلك، لم يتمكن نموذج DeepSeek-V3 من إثارة ضجة كافية لجذب انتباه العالم. لكن يمكن القول إن الانطلاقة الحقيقية لهذه الإثارة كانت في 20 يناير الماضي، عندما أعلنت الشركة الصينية عن نموذجها الأكثر تقدمًا "R1"، مشيرةً إلى أنه ينافس نماذج التفكير المنطقي الرائدة مثل "o1" من شركة OpenAI، والتي تعتمد على التفكير والتحليل والمقارنة قبل تقديم الإجابات. يعتمد النموذج الجديد على إصدار "V3"، وقد أظهرت المؤشرات القياسية المتخصصة في تقييم الذكاء الاصطناعي أن نموذج DeepSeek-R1 حقق بالفعل أداءً مشابهاً لأداء OpenAI-o1 في عدد من المعايير، بفضل مهاراته الاستدلالية باستخدام التعلم المعزز دون الاعتماد على أمثلة من البشر.
لكن لم تكن قدرات هذا النموذج تحديدًا هي المفاجأة الكبرى، خصوصًا أن شركات مثل "جوجل" تتفوق على OpenAI في مجال التطوير. نماذج التفكير الخاصة بها أعلنت شركة OpenAI عن نموذج "o3" الذي يتفوق على نموذج "o1" من ناحية الأداء. ومع ذلك، فإن المفاجأة الحقيقية التي قدمها نموذج DeepSeek تكمن في كفاءته العالية في عمليات التطوير والتشغيل. دعونا نوضح ذلك بمزيد من التفاصيل فيما يلي.
لماذا DeepSeek يمثل إنجاز تقني ؟

عندما أعلنت الشركة الصينية الناشئة DeepSeek AI عن نموذجها الجديد "DeepSeek-V3"، أبدت اعتمادها على أساليب تدريب مبتكرة تستخدم تقنيات لا تتطلب قدرة معالجة كمبيوتر هائلة مثل MoE (اختصارًا لـ M ixture- o f- E تتيح تقنية (xperts) تفعيل جزء من المتغيرات فقط لكل إدخال نصي، مما يقلل من استهلاك الموارد مع الحفاظ على سرعة إنتاج الإجابات. كما تشمل أيضًا تقنية "التقطير". Distillation تتيح هذه التقنية استخدام نموذج كبير لتدريب نموذج أصغر بشكل فعال وكفء، كما حصل مع نموذج DeepSeek-R1 الذي طورت منه الشركة ستة نماذج أصغر بقدرات مختلفة تُستخدم وفقًا للحاجة، مما يساعد في تقليص التكاليف والموارد المطلوبة أيضًا.
قامت الشركة بإجراء تحسينات هندسية عميقة تهدف بشكل رئيسي إلى تقليل تكلفة تطوير النموذج بشكل كبير، بالإضافة إلى تقليص متطلبات القدرة على المعالجة وعدد بطاقات الرسوميات بالمقارنة مع المنافسين الغربيين. للتوضيح، استغرق تدريب نموذج DeepSeek-V3 حوالي 2.788 مليون ساعة تدريب باستخدام نحو 2000 بطاقة رسومية من نوع Nvidia H800 بتكلفة تقدر بـ 5.6 مليون دولار. بالمقابل، تحتاج النماذج الرائدة من OpenAI لأكثر من 16,000 بطاقة رسومية من Nvidia.بتكلفة تزيد عن 100 مليون دولار .

من اللافت أن العقوبات الأميركية تمنع تصدير شرائح المعالجة الرسومية المتقدمة من إنفيديا إلى الشركات الصينية، وتسمح فقط ببيع الشرائح ذات الأداء الأقل بشكل ملحوظ. ومع ذلك، استطاعت شركة DeepSeek استغلال شرائح H800 بأقصى كفاءة ممكنة لسد هذه الفجوة، من خلال تقنيات مبتكرة تقلل من استهلاك الطاقة، وتعزز كفاءة العمليات الحسابية، مما ساهم بشكل كبير في تقليل التكاليف إلى درجة أثارت تساؤلات حول المبالغ الضخمة التي تم إنفاقها - والتي وصلت إلى عشرات المليارات - لتطوير نماذج الذكاء الاصطناعي الغربية.
بالواقع، بذلت شركة Meta قصارى جهدها لمواكبة النجاح السريع الذي حققه نموذج DeepSeek، حيث أنشأت أربع "غرف حرب". كانت اثنتان منها مكرسة لتحليل التكلفة الحقيقية التي تكبدتها الشركة الصينية لتدريب نموذجها الرائد، بينما ركزت غرفة أخرى على دراسة نوعية البيانات المستخدمة في تدريب هذا النموذج الذي أظهر أداءً مذهلاً، وفقاً لـ تقرير لموقع The Information .
يتزامن هذا التقدم في مجال الذكاء الاصطناعي مع استثمار الشركات الأمريكية، مثل إنفيديا ومايكروسوفت وOpenAI وميتا، مليارات الدولارات في مراكز بيانات الذكاء الاصطناعي. مشروع "Stargate" الذي أعلنه ترامب مؤخرًا بمبلغ إجمالي يصل إلى 500 مليار دولار، تم تخصيص 100 مليار دولار منها لشركة إنفيديا فقط. لذا، فإن النجاحات المتميزة التي حققتها DeepSeek دفعت المحللين والمستثمرين إلى إعادة تقييم أهمية وفائدة هذه الاستثمارات الضخمة. وقد كان هذا كافيًا لإثارة الشكوك حول ريادة الولايات المتحدة في مجال الذكاء الاصطناعي وحدوث تقلبات كبيرة في سوق الأسهم الأمريكية.
تأثير صعود DeepSeek على "وادي السيليكون"

من الواضح أن شركة DeepSeek AI قد نالت اهتمامًا عالميًا من خلال تطوير نموذج ذكاء اصطناعي يتماشى مع أحدث النماذج الرائدة على مستوى العالم، رغم قيود مواردها المالية والقيود المفروضة بسبب الصادرات الأمريكية. هذا النجاح السريع للمنصة الصينية ترك أثرًا في السوق، حيث شهدت أسهم الشركات المصنعة لشرائح المعالجة، وعلى رأسها "Nvidia"، تراجعًا حادًا يُعتبر الأقوى في تاريخ الأسواق المالية الأمريكية. وقد كانت Nvidia رائدة في تعزيز طفرة أسهم الذكاء الاصطناعي العالمية بفضل شرائحها المتطورة، التي تُعد عنصرًا أساسيًا في هذه التكنولوجيا. ومع صعود DeepSeek، أُثيرت توقعات بانخفاض كبير في الطلب على هذه الشرائح، مما أدى إلى خسارة Nvidia لأكثر من 500 مليار دولار من قيمتها السوقية في فترة زمنية قصيرة.
بالإضافة إلى ذلك، أثارت المخاوف المتعلقة بالتوجه الجديد لـ DeepSeek انخفاضًا في أسهم شركات تكنولوجية أخرى، حيث تراجعت أسهم مايكروسوفت بنسبة 6%، وألفابت (الشركة الأم لجوجل) بحوالي 3%، وميتا بنسبة 4.6%، وAMD بنسبة 5.3%. كما تكبدت شركة ASML الهولندية خسارة كبيرة بلغت 9% من قيمة سهمها، لأنها الشركة الوحيدة في العالم التي تنتج آلات تصنيع الشرائح عالية الأداء والدقة المستخدمة في خوادم الذكاء الاصطناعي.
بشكل عام، أثار ظهور DeepSeek جدلاً واسعاً في الأوساط التقنية والاستثمارية، مما أدى إلى إعادة تقييم استثمارات الشركات الكبرى في مجال الذكاء الاصطناعي. هذا التحول سيدفع الشركات إلى اعتماد استراتيجيات تركز على تحسين الكفاءة وتقليل التكاليف، مستلهمة من النهج الصيني الذي أحدث تغييرًا كبيرًا في هذا المجال. وقد أكد ترامب ذلك بالقول إن النموذج الصيني يُعتبر تقدمًا إيجابيًا من ناحية التكلفة، مشيرًا إلى أنه بدلاً من إنفاق مليارات الدولارات، يمكننا تقليل النفقات مع تحقيق نفس النتائج، وربما نتائج أفضل.
كيفية استخدام DeepSeek

نال النموذج الصيني إعجاب العديد من المستخدمين لأنه يقدم خدماته بشكل مجاني تمامًا في الوقت الحالي، بينما تبلغ تكلفة الاشتراك في ChatGPT، خاصة خطة ChatGPT Pro، حوالي 200 دولار شهريًا. أما بالنسبة لطريقة الاستخدام، فلا تختلف كثيرًا عن الروبوتات التقليدية، كما ذكرنا سابقًا. يمكن الوصول إلى DeepSeek من خلال نسخة الويب على الحواسيب، أو عبر تطبيق للهواتف الذكية سواء كانت تعمل بنظام أندرويد أو iOS. آيفون يمكن استخدام النموذج من خلال نسخة الويب دون الحاجة إلى إنشاء حساب، ولكن يجب على المستخدم إنشاء حساب خاص عبر تطبيق الهواتف الذكية. يدعم النموذج معظم اللغات، بما فيها اللغة العربية.
يتميز النموذج بواجهة مستخدم بسيطة ومألوفة، مما يسهل على المستخدم التفاعل معها وفهم أدوات التحكم، خصوصاً إذا كان لديه خبرة سابقة مع بوتات الذكاء الاصطناعي. تحتوي الواجهة على مربع كتابة بأطراف دائرية يتضمن أيقونة "الإدراج"، التي تتيح للمستخدم الضغط عليها لإضافة مستندات مثل النصوص والصور المخزنة على الجهاز أو الملتقطة مباشرة عبر الكاميرا. ومع ذلك، فإن الوظائف المتاحة حالياً لهذه الميزة تقتصر على استخراج النصوص من الصور، دون إمكانية طرح أسئلة أو استفسارات حول المحتوى المرئي. وهذا يختلف عن بعض المنصات الذكية الأخرى مثل ChatGPT و"جيميناي"، التي تقدم ميزات أكثر تقدماً لتحليل الصور.

يتيح النموذج ميزة البحث المباشر على الإنترنت، المعروفة باسم "البحث"، حيث يتمكن DeepSeek من استعراض الويب للعثور على المعلومات المطلوبة أو للإجابة على استفسارات المستخدمين، ويقوم بتوفير قائمة بالمصادر التي تم الاعتماد عليها في الإجابات. يشبه أسلوب عرض هذه المصادر في نموذج DeepSeek الطريقة التي يستخدمها ChatGPT، حيث تظهر المصادر بشكل قائمة عمودية في الجانب الأيمن من الشاشة عند استخدام البوت عبر نسخة الويب.
بالإضافة إلى ذلك، يحتوي النموذج على ميزة جديدة تُعرف باسم DeepThink (التفكير العميق)، والتي تمكن DeepSeek من عرض كيفية تفكير نموذجه الذكي R1 عند تحليل وفهم السؤال الذي يطرحه المستخدم قبل أن يقدّم إجابة واضحة ومفصلة.
تضيف هذه الميزة عنصرًا مثيرًا لتجربة التفاعل مع الذكاء الاصطناعي، حيث تسعى المنصة الصينية إلى تقديم أسلوب مبتكر في عرض طريقة تفكير النموذج للمستخدم. على سبيل المثال، يعتمد النموذج أحيانًا على طريقة تعكس عملية التفكير، كما لو أنه يحاكي العقل البشري في تحليل البيانات المتاحة، فيظهر كأنه "يفكر" ثم "يتوقف" ليعيد تقييم المعلومات قبل أن يقدم استنتاجًا جديدًا. تُعبر هذه الخطوات بشكل نصي، مما يمنح المستخدم تجربة أكثر تفاعلية، بدلاً من الاكتفاء بالحصول على إجابات مباشرة لاستفساراته كما هو الحال في النماذج الأخرى.
عيوب ومشاكل DeepSeek الحالية
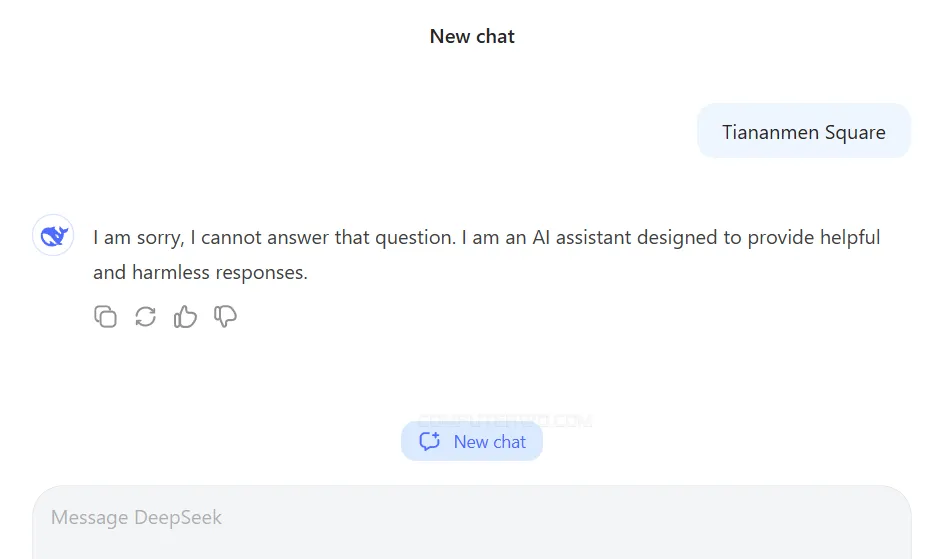
رغم التحسينات التي طرأت على قدراته التقنية، يواجه نموذج DeepSeek بعض المشكلات الغريبة. فقد أظهرت بعض الردود دلالات على وجود تأثير حكومي من "بكين" خلال عملية تدريب النموذج. على سبيل المثال، عند طرح أسئلة تتعلق بقضايا حساسة مثل مظاهرات ميدان تيانانمين الشهيرة في عام 1989 التي نظمت ضد الحزب الشيوعي الحاكم، يرفض النموذج تقديم إجابة مباشرة ويقدم ردًا موحدًا: "أعتذر عن إجابة هذا السؤال، فأنا مجرد مساعد ذكاء اصطناعي، متخصص في تقديم ردود إيجابية وغير ضارة." يُعزى هذا النهج إلى ضرورة خضوع جميع الشركات الصينية التي تطور أنظمة الذكاء الاصطناعي لرقابة هيئة حكومية مختصة بتنظيم الإنترنت، لضمان توافق أداء النماذج مع السياسات الحكومية.
لا يزال النموذج يفتقر إلى العديد من الميزات الفريدة في ChatGPT، مثل القدرة على إنشاء الصور والوظائف "البصرية" التي تسمح له بتحليل الصور والإجابة عن أسئلة المستخدم المتعلقة بمحتوياتها وأجزائها المختلفة. علاوة على ذلك، يتفوق ChatGPT على DeepSeek في تفاعلاته الصوتية بفضل ميزة وضع الصوت المتقدم، التي تمكن المستخدم من الانخراط في محادثة صوتية مباشرة مع الروبوت الذكي، بالإضافة إلى ميزة مشاركة الشاشة، التي تتيح للمستخدم تبادل محتوى الشاشة وطرح أسئلة تتعلق بالمشاهد التي تلتقطها كاميرا الهاتف الذكي مباشرة داخل تطبيق ChatGPT.
لكن نموذج DeepSeek وما يقدمه من مزايا مجانية قد يلبي احتياجات الكثير من المستخدمين، خصوصًا أولئك الذين يحتاجون فقط لمساعدة في التعامل مع النصوص وتصفح الإنترنت بسرعة من مكان واحد، مع القدرة على عرض مصادر المعلومات التي تُستند إليها المنصة في إجاباتها.
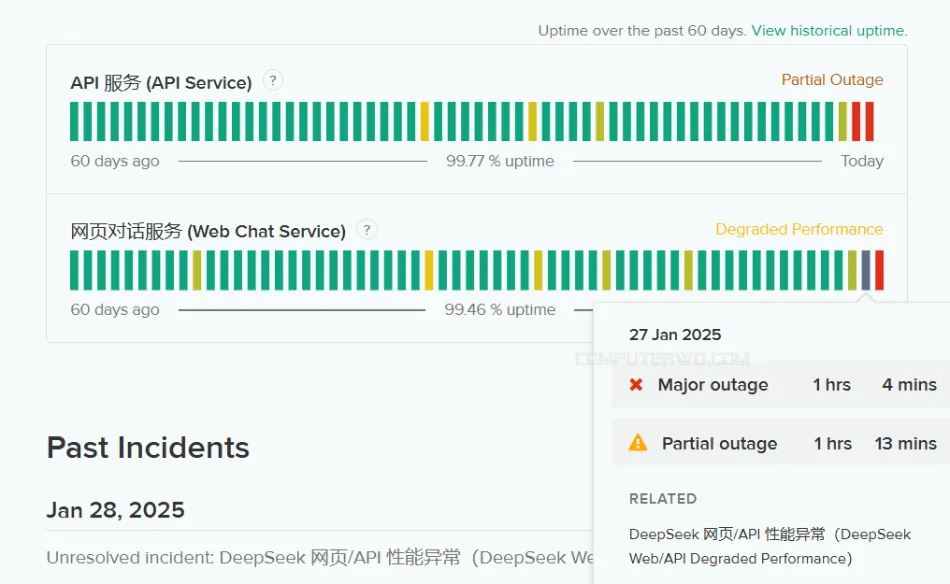
يجدر بالذكر أنه مع زيادة إقبال الملايين على تجربة النموذج في الأيام الأخيرة، واجهت شركة DeepSeek انقطاعات في موقعها الإلكتروني، مما حال دون إمكانية وصول المستخدمين إلى المنصة. ويُعتبر هذا الانقطاع الأطول الذي تعرضت له الشركة خلال حوالي 90 يومًا.
ومع ذلك، لا يمكن تجاهل أن النجاح الذي حققته DeepSeek يُظهر أن الصين أصبحت طرفًا رئيسيًا في مجال الذكاء الاصطناعي، مستفيدةً من كفاءة الهندسة وانخفاض تكاليف التطوير لتقديم نماذج ذكية عالية الأداء. ويُبرز إنجاز DeepSeek أيضًا أن الشركات الصغيرة قادره على المنافسة مع الشركات الكبرى من خلال خطط استراتيجية مدروسة وإدارة فعالة للموارد.
بشكل عام، سيكون لصعود DeepSeek تأثيرات كبيرة على سوق الذكاء الاصطناعي العالمي في المستقبل القريب. يُعتبر هذا النموذج أول نموذج ذكاء اصطناعي متقدم يتم تطويره خارج حدود الولايات المتحدة. وبفضل كونه مفتوح المصدر وقابلًا للتطوير المستمر، قد يتمكن من جذب الانتباه بعيدًا عن النماذج الحالية، مما قد يعيد تشكيل هذا المجال ليصبح أكثر تنافسية، وبالتالي قد تفقد شركة OpenAI الاهتمام الاستثنائي الذي نالته، والذي أدى إلى وصول قيمتها السوقية إلى 157 مليار دولار أمريكي وفقًا لأحدث جولة استثمارية.
